-
Type:
Bug
-
Resolution: Fixed
-
Priority:
 Low
Low
-
Affects Version/s: 6.4.12, 7.2.12, 7.5.1, 7.6.7, 7.13.3, 8.5.3, 8.7.0
-
Component/s: Data Center - Other
-
6.04
-
70
-
Severity 2 - Major
-
335
-
Summary
Assume some node in JIRA Datacenter is executing long running task with has cluster wide status. If at some point progress abnormally stops before the job is complete, then job will be stuck for whole cluster.
The stuck job is stored in an in-memory cache and is replicated to other nodes when they start. All nodes must be shutdown at the same time in order for this job to be removed from cache.
Environment
- JIRA DataCenter with 2+ nodes
Steps to Reproduce
- Performs change that causes "Bulk Operation" action
- Monitor "Bulk Operation Progress" bar.
- Restart the node executing job (or create database connection failure)
Actual Results
- Progress bar appears in stuck state on each node.
- A restart of one node has no impact, progress bar continues to appear.
- The stuck job appears when trying to make other changes. Other changes cannot be made while this is stuck.
- All nodes must be shutdown at the same time in order for this job to be removed from cache.
Expected Results
Either:
- JIRA cluster detects the job is no longer progressing, throws an error, and no longer shows the stuck "Bulk Operation Progress" bar.
- Or JIRA cluster detects the job is no longer progressing and continues the job
In either case, a stuck job on one node does not require restart of entire cluster
Notes
- A stuck bulk edit can be reproduced by setting a breakpoint to stop thread on BulkEditOperation.java line 184.
- The bulk edit task is in memory and is communicated to all nodes.
- Nodes will keep this task in memory until it is deleted, or all nodes are down (clearing tasks in memory)
- Task is deleted when the operation is complete. Operation happens on the node the task started on.
Workaround
In some cases, it may possible to manually delete the stuck job. This should only be done after being absolutely certain that the job is no longer running.
Example for project migration, workflow migration , and bulk edits :
- This needs to be run by the user who executed the task. In addition the user must be a JIRA Administrator in order to delete the task.
- If necessary grant temporary admin permission, delete task, then remove admin permission.
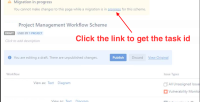
- If you are looking for the task id, you can click on the Workflow page where it says Migration in progress then click on the progress in blue. The task id should be on the page URL. Then replace the Id to the #id curl command below:
- URL below applies to bulk edits as well as project changes
There is a internal REST point to stop tasks.
- DELETE /rest/projectconfig/1/migrationStatus/#id
- "#id" can be taken from the progress page's URL.
- If necessary grant temporary admin permission, delete task, then remove admin permission.


- causes
-
-

- Closed
-
-
JRASERVER-66722 As an JIRA Datacenter Administrator I want to delete stuck global tasks
- Closed
-
- Closed
-
- Closed
- depends on
-
- Closed
- is related to
-
-
- Closed
-
-
- Gathering Interest
-
SSE-602 Loading...
- relates to
-
-

- Gathering Impact
-
-
- Gathering Interest
-
- Mentioned in
- mentioned in
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-