-
Type:
Bug
-
Resolution: Timed out
-
Priority:
 Low
Low
-
3
-
Minor
Issue Summary
The Jira Timeline (previously Roadmap) uses a filtering function to hide 'done' Epics older than x months. Under the hood, this relies on the statusCategoryChangedDate field value.
This particular field is not included in the output when you "Export CSV (all fields)" from the issue navigator, and as a result, on import, that field value gets set to the current date (which in turn breaks the Timeline 'done' filtering as the dates are no longer correct)
Steps to Reproduce
- Export an Epic via the issue navigator CSV export with a resolution date > 1 month
- Import this data
- Go to the Jira Timeline, and set the Issue display range view setting to Show Epic issues completed in the last 1 month
Expected Results
The imported Epic should not show on the Timeline, as it's statusCategoryChangedDate date is the same as the exported Epic (> 1 month)
Actual Results
The imported Epic shows on the Timeline, as it's statusCategoryChangedDate has been set as the current date on import.
Workaround
- Export issues with HTML report export option
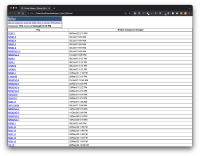
- Run the below script on the HTML

from bs4 import BeautifulSoup import csv # Replace 'your_html_file.html' with the name of your HTML file html_file = 'your_html_file.html' with open(html_file, 'r') as file: html_doc = file.read() soup = BeautifulSoup(html_doc, 'html.parser') rows = soup.find_all('tr', class_='issuerow') data = [] for row in rows: issue_key = row.find('a', class_='issue-link')['data-issue-key'] status_category_changed = row.find('td', class_='statuscategorychangedate').get_text(strip=True) data.append([issue_key, status_category_changed]) csv_file = "extracted_data.csv" with open(csv_file, 'w', newline='') as csvfile: writer = csv.writer(csvfile, delimiter=',') writer.writerow(['Key', 'Status Category Changed']) writer.writerows(data)
- Append the generated column to the CSV export to be imported







- is related to
-
JRACLOUD-82605 [Tracked in Issue Links] tickets related to issue exports (CSV, HTML Report, Excel etc)
- Gathering Interest
-
ROAD-6770 Loading...