-
Type:
Bug
-
Resolution: Fixed
-
Priority:
 Low
Low
-
Affects Version/s: 7.2.3, 7.3.1
-
Component/s: Data Center - Other
-
7.02
-
23
-
Severity 2 - Major
-
69
Summary
- When a node is removed from JIRA Data Center, it is not possible to login for about 5-10 minutes.
- A use case of node removal is when AWS Auto Scaling Group (ASG) is used where nodes are added or removed as the overall load increases or decreases.
Environment
- Using the Cloud Formation (CF) templates from Atlassian/AWS to setup a JIRA data center environment in AWS.
- Reference: JIRA Software and JIRA Service Desk Data Center on the AWS Cloud.
Steps to Reproduce
- Setup JIRA Data Center in AWS.
- Ensure to have more than 3 nodes configured for Minimum number of cluster nodes.
- Wait for all the nodes to be alive from the System Info page on JIRA:
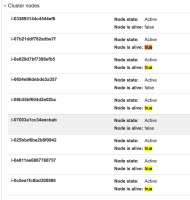
- Update the Cluster nodes to have 2 Minimum and Maximum 2 nodes:
- Check the CloudFormation page to ensure that the status shows UPDATE_COMPLETE.

- Check if the nodes are being removed from the System Info page on JIRA. Only 2 nodes should be Alive.




Expected Results
- Users should be able to log in.
- Existing users should not be logged out when nodes are being removed.
Actual Results
- Users are unable to login JIRA for about 5-10 mins.
- Getting the error that the username or password is invalid.
- Existing users get logged out of JIRA.
- The below exception is thrown in the atlassian-jira.log file:
2017-03-01 11:23:30,330 http-nio-8080-exec-19 WARN anonymous 683x44x2 ju0bau 211.25.18.162,10.0.141.167 /login.jsp [c.a.j.cluster.distribution.JiraCacheManagerPeerProvider] Looking up rmiUrl //ip-10-0-55-196:40001/com.atlassian.jira.avatar.CachingTaggingAvatarStore.avatars threw a connection exception. This could mean that a node has gone offline or it may indicate network connectivity difficulties. Details: Exception creating connection to: ip-10-0-55-196; nested exception is: java.net.NoRouteToHostException: No route to host 2017-03-01 11:23:39,594 http-nio-8080-exec-10 WARN anonymous 683x60x2 ju0bau 211.25.18.162,10.0.141.167 /rest/gadget/1.0/login [c.a.j.cluster.distribution.JiraCacheManagerPeerProvider] Looking up rmiUrl //ip-10-0-35-163:40001/com.atlassian.jira.crowd.embedded.ofbiz.EagerOfBizUserCache.userCache threw a connection exception. This could mean that a node has gone offline or it may indicate network connectivity difficulties. Details: Exception creating connection to: ip-10-0-35-163; nested exception is: java.net.NoRouteToHostException: No route to host 2017-03-01 11:23:42,598 http-nio-8080-exec-10 WARN anonymous 683x60x2 ju0bau 211.25.18.162,10.0.141.167 /rest/gadget/1.0/login [c.a.j.cluster.distribution.JiraCacheManagerPeerProvider] Looking up rmiUrl //ip-10-0-55-196:40001/com.atlassian.jira.crowd.embedded.ofbiz.EagerOfBizUserCache.userCache threw a connection exception. This could mean that a node has gone offline or it may indicate network connectivity difficulties. Details: Exception creating connection to: ip-10-0-55-196; nested exception is: java.net.NoRouteToHostException: No route to host 2017-03-01 11:24:04,350 Caesium-1-2 WARN ServiceRunner [c.a.j.cluster.distribution.JiraCacheManagerPeerProvider] Looking up rmiUrl //ip-10-0-35-163:40001/com.atlassian.jira.plugins.healthcheck.service.HeartBeatService.heartbeat threw a connection exception. This could mean that a node has gone offline or it may indicate network connectivity difficulties. Details: Exception creating connection to: ip-10-0-35-163; nested exception is: java.net.NoRouteToHostException: No route to host 2017-03-01 11:24:07,354 Caesium-1-2 WARN ServiceRunner [c.a.j.cluster.distribution.JiraCacheManagerPeerProvider] Looking up rmiUrl //ip-10-0-55-196:40001/com.atlassian.jira.plugins.healthcheck.service.HeartBeatService.heartbeat threw a connection exception. This could mean that a node has gone offline or it may indicate network connectivity difficulties. Details: Exception creating connection to: ip-10-0-55-196; nested exception is: java.net.NoRouteToHostException: No route to host 2017-03-01 11:25:37,666 http-nio-8080-exec-19 WARN anonymous 683x44x2 ju0bau 211.25.18.162,10.0.141.167 /login.jsp [c.a.j.cluster.distribution.JiraCacheManagerPeerProvider] Looking up rmiUrl //ip-10-0-30-161:40001/com.atlassian.jira.avatar.CachingTaggingAvatarStore.avatars threw a connection exception. This could mean that a node has gone offline or it may indicate network connectivity difficulties. Details: Connection refused to host: ip-10-0-30-161; nested exception is:
Root cause
Ehcache in JIRA DC is not informed about node being removed from the cluster. As a result for about 5 minutes all nodes in the cluster will try to invalidate cache on not existing host. Resolving host name that is not existing is much slower than for existing host, this is why this problem is occurring.
In order to prevent this from happening first shut down JIRA, wait 5-10 minutes and then terminate the host itself.
Notes
- Issue is reproducible when the node is removed by ASG or removed/terminated manually.
- This not only affects AWS but also generic Data Center environments when host DNS name becomes unavailable.
Workaround
For AWS, do not use Auto Scaling Group by configuring the Minimum number of cluster nodes identical to the Maximum number of cluster nodes.




- is caused by
-
-
- Closed
-
- is related to
-
-

- Closed
-
- relates to
-
PSR-49 Loading...