-
Type:
Bug
-
Resolution: Won't Fix
-
Priority:
 Low
Low
-
None
-
Affects Version/s: None
-
Component/s: Data Center
-
None
-
Severity 3 - Minor
Summary
HipChat Data Center scissortail process fails on node(s) after 1 of the nodes get terminated through the AWS console.
Environment
- HipChat Data Center AWS deployment
Steps to Reproduce
- Deploy the HipChat Data Center AWS through the CloudFormation template - https://s3.amazonaws.com/hipchat-server-stable/dc/production/templates/quickstart-hipchat-master.template
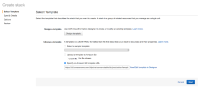
- Under the RDS database password field in the Specify details page, include a # character in the PostgreSQL password. For example - 123PostgreSQL#
- Complete the deployment and ensure that all 3 nodes are up and running
- Once done, terminate one of the nodes so that the Auto Scaling Groups kicks in and deploy a new node
- SSH to the bastion host then into all the nodes to confirm the status of scissortail


Expected Results
The scissortail processes should be up and running
Actual Results
The processes are down as per the following outputs:
admin@ip-10-10-10-13:~$ sudo dont-blame-hipchat -c "monit summary" The Monit daemon 5.16 uptime: 12m Process 'tetra-proxy-6' Running Process 'tetra-proxy-5' Running Process 'tetra-proxy-4' Running Process 'tetra-proxy-3' Running Process 'tetra-proxy-2' Running Process 'tetra-proxy-1' Running Process 'tetra-proxy-0' Running Process 'tetra-app-5' Running Process 'tetra-app-4' Running Process 'tetra-app-3' Running Process 'tetra-app-2' Running Process 'tetra-app-1' Running Process 'tetra-app-0' Running Process 'sshd' Running Process 'scissortail-web-0' Does not exist Process 'rsyslog' Running Process 'punjab' Running Process 'php5-fpm' Running Process 'nginx' Running Process 'integrations-0' Running System 'localhost' Running Process 'gearmand' Running Filesystem 'xvda1' Accessible Filesystem '333411ff-71fc-42c0-a7bc-1e61068a5985' Accessible Process 'curler' Running Process 'crowd' Running Process 'coral-5' Running Process 'coral-4' Running Process 'coral-3' Running Process 'coral-2' Running Process 'coral-1' Running Process 'coral-0' Running Process 'barb-0' Running
admin@ip-10-10-10-13:~$ sudo dont-blame-hipchat root@ip-10-10-10-13:/home/admin# /etc/init.d/scissortail-worker-0 status * Status of scissortail-worker0... not running and the pid file exists root@ip-10-10-10-13:/home/admin# /etc/init.d/scissortail-web-0 status * Status of scissortail-web0... not running and the pid file exists root@ip-10-10-10-13:/home/admin# /etc/init.d/scissortail-web-0 restart * Stopping scissortail-web-0... not running * Starting scissortail-web-0... done root@ip-10-10-10-13:/home/admin# /etc/init.d/scissortail-worker-0 restart * Stopping scissortail-worker-0... not running * Starting scissortail-worker-0... done
This defeats the purpose of the warning message that is displayed if the password was not set according to the password policy:

This will cause hipchat export and import to fail:
admin@ip-10-10-10-13:~$ hipchat export -e -p scissorTAIL123 Error: Can't reach the hipchat services. () Completed
admin@ip-10-10-10-13:~$ hipchat import -i -u /home/admin/test.tar.gz -p scissorTAIL123
Error: Can't reach the hipchat services.
()
Completed
Workaround
Exclude the # from the password before deploying the CloudFormation template again
Solution
Either fix the bug so a "#" or "$" doesn't cause it or add a warning to the CloudFormation template for admins not to use "#" nor "$" in the password.




