Summary
Currently, it is not possible to create a new sprint when importing issues from CSV.
You can only map the issues to an existing sprint in your instance.
Suggestion
You can even select the map option when importing, but it expects a number (the id of the existing sprint):
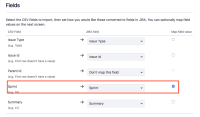
Perhaps, there could be the possibility of sending a string so Jira could create a sprint using that string as the sprint's name.
Current workaround
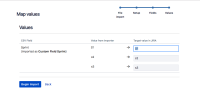
As stated before, you can only map to an existing Sprint in your instance by parsing an id (corresponding to the sprint's id). So you need to create the desired sprint before the import.
1. Finding the id of a sprint:
- Perform an advanced search towards the Sprint field: Sprint = sprint:
- When the possible options are displayed (name of existing sprints), their id are displayed next to their name:

- Also, when selecting one of the sprints, their id will remains as the parameter for the search:

2. Use the id corresponding to the desired sprint in your CSV file
- Example:

- Of course, you can also check the map option during the import to change the current values to the corresponding ids:

Suggestion
















